
Go服务分布式链路追踪系统的设计
why
首先
为什么需要有这个链路追踪系统?
首先先从业务的角度来进行思考
某些业务情境下 例如说是消息下发 支付 或者等等
当我们需要在发起执行业务的请求后 需要获取业务的执行情况、执行进度的时候 可以通过这个链路追踪系统中的信息获取
然后也是最主流的使用情景 —— 在运维、开发、测试的时候
假如某个程序报了始料未及的错误 由于是微服务情境下 多台机器的使用会导致很难纠错
而这个分布式链路追踪系统则可以很直观的告诉开发者 是哪里报了错 快速的定位错误 定性错误
这样的轮子现在已经有很多了 这里所体现的是在具体场景下的一些优化
首先就是
在应用体量很大 数据量很多的时候 这时候应该怎么进行处理
这时候会带来很多问题 首先就是数据量大 想要查询日志的话 本身的耗时成本 查询时所带来的CPU成本
假如是业务功能的话 这个查询的频率会更高 所带来的劣势也会更大
还有一个最显而易见的存储成本的问题 不同的云存储成本
如何优化呢?
首先一种方式就是 流处理 + 批处理 利用Spark或者是Flink等组件
还有一种思路 也就是这里所主要进行的优化是 摒弃完全的中心化存储 转为去中心化存储
在多台服务实例的前提下 将数据分到不同的存储机器上
初次之外 还可以 优化查询的方式 以及 日志本身的存储格式
查询格式
Before
这里先从查询的方式进行谈起 后方的消息格式 存储均由此引出
传统的消息追踪系统一般来说 就是将相关消息打到中心化存储介质上 然后获取该次请求的相关信息
并会根据消息前缀k-v做对应的分片和优化 大体是这样的思路
当用户想要查的时候 根据这个id 到对应的shard中进行一个类似全表扫描或get的过程
上述是一个大体的思路 当某个请求需要打多个锚点的时候 就需要进行一个人为的定位
After
类比DNS的查询域名方式
首先对于每个上游or下游服务都设计对应的存储介质
仅保留一个查询的接口 当查询请求来到的时候 先从上游服务的存储中查起
如果成功查到了 就代表此时该服务锚点是正常运行的 并且此时上游存储服务会返回一个下游服务的标识
然后通过这个服务继续往下查 如果查到了 就代表此时该服务阶段正常运行 不断往下游服务进行遍历
如果迭代查到最后 消息体中next标识为空 则代表此时是正常运行的
如果在某个位置 存在next标识 但是在对应的服务中却找不到
则代表当前服务是最后一个正常运行的坐标 该次请求在下一个服务处panic返回
整个查询的流程是和DNS到根、顶级、权威服务器中查询很像的
服务器到其查询 查询到了就返回 进行下一个阶段的查询
消息格式(TraceID)
从上方可以引出 在这个方案下 设计的要求有:
- 全局唯一,单请求下不同服务日志信息间也保持唯一
- 带有服务标识信息,可以找到对应服务请求的入口实例
除此之外 还需要保证 单调递增,让日志消息可以进行排序
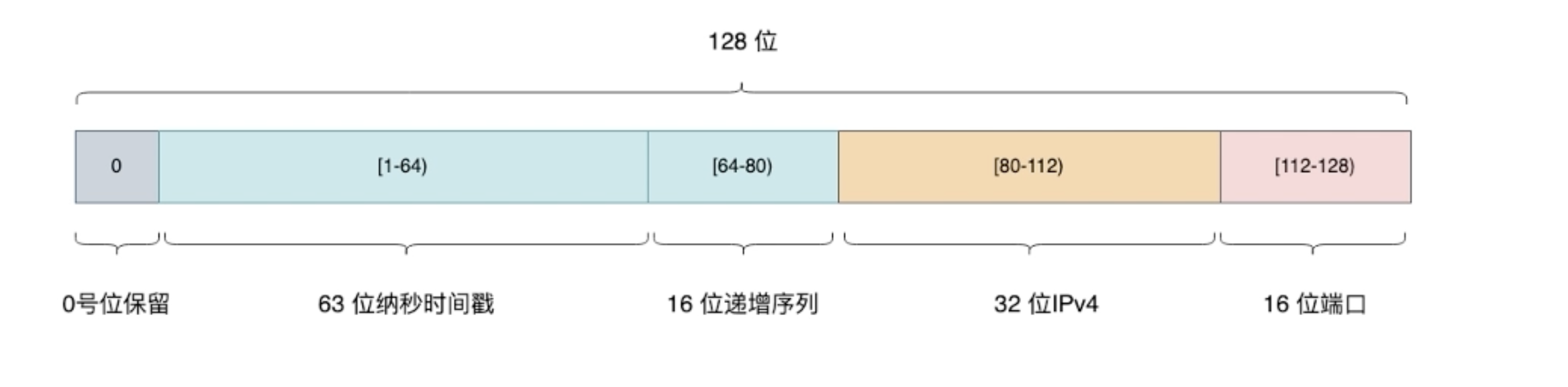
上图所表示的就是一个基本的消息格式
通过纳秒级时间戳+数位 保证了每个日志信息的一致性 (数位表示的是 当纳秒时间戳都一致的时候 就使用这个二进制数位作为区分) 这样就满足一般场景下所会产生的并发
通过ipv4 + port 本质上就得到了当前的下游服务的地址 服务端可根据此信息转发到下游服务
这里虽然说使用时间戳保证了每个信息的递增 但是本质上还是会存储的时候 还是会乱序 后方会提到
这里的去中心化也许会带来所谓的一致性问题?
不必然 首先需要思考一致性问题出现的前提条件: 在同一时刻 存在数据延迟 从而导致了同时存在两个不同版本的数据
分布式链路追踪系统的信息对于单台机器 只有其本身的一个状态 不会存在冗余信息 不会保存他的上游or下游的状态 即: 每一条追踪信息本身是无状态的
可以理解为 每个请求所到来的时候 每个锚点信息本身是原子且一致的
所以就不用担心一致性问题
存储介质
可以选择将数据存到MySQL或Redis中 然后扫描获取的时候 根据筛选条件直接获取
这里所采用的是Hbase 优点有:
Mysql是按行存储数据的 他的写本质上是一个覆盖写
例如说 当要更新某个语句为 id = 1 的时候
mysql是先去对应数据库中查 查到了之后 就将该行的数据原地更新(并且他的一些优化都是围绕这个思路来进行优化的)
这也是由于他的底层是通过B+树来进行实现的 然后在他之上的修改的话 也是围绕着“尽量不修改原有树结构的思路进行的”
而Hbase的写是追加写 在他需要更新数据的时候 他不会关注之前的这些数据是否存在 而是直接写一个新的版本
当读取数据的时候 就将读取到的多个版本进行合并
同理 在新增数据上 由于Hbase在写数据的时候 不需要关注是否会影响当前的数据存储结构(没有诸如B+树的限制)所以他的写速度会更高
这一变化在数据量大的时候 更加明显
但是这一追加写模式也有其劣势 即 读取数据的时候 mysql只需要onlogn的效率 读取到对应的一行数据即可
但是追加写模式下 Hbase需要定位到对应的行数据当中 假如之前有对数据更新过 他需要对这些消息都做一个版本的合并
即 当数据 更新频率高 读取频率高的时候 他的效率就会显著的受影响 而B+树则在这一场景下表现更加均衡
然后 在当前的业务场景下 单服务中链路追踪的信息修改频率可以认为是极低的
所以可以直接利用Hbase的高效写 使用它作为存储介质
Hbase底层的实现是LSM-Tree 主要是利用顺序写 这也是它能高效写的一个原因之一
存储优化
在确定了存储中间件为Hbase之后 可以制定一些相对应的优化措施
首先最老生常谈的就是 将单独写修改为批量写
将段时间内的数据装到滑动窗口中 并且批量顺序写的形式写入DB当中
如上方所说 虽然已经使用了时间戳实现一个递增
但是每个请求的网络IO耗时时间不相同 这就导致了这样的情况:
A请求在15:00发起 网络中运行了10s 15:10到达
B请求在15:03发起 网络中运行了5s 15:08到达
上面的情况中赋予traceID是B的比较大 但假如说两个服务经过了某些个共用的节点 就有可能会导致两者之间的乱序 —— 先有B的日志 再有A的日志
面对这样的局部乱序 首先就可以通过上方的批量写 将信息聚合到窗口中
然后标记出该窗口的max和min 在查询的时候如果进行了范围查询 只需要返回当前窗口or两个窗口聚合中的结果即可
还有一个显著减小存储成本的方式就是压缩
在mysql中 数据是按行记录的 每一行的记录值区分度一般情况下会比较高
但是Hbase中是列式存储的 ——> 数据区分度低 ——> 数据压缩时能带来更优的效果
综
综上 当查询数据的时候 面对目前的方案 只需要向上游服务发起一个请求 就可以自动递归到出问题的下游服务
去中心化的存储架构下 同时保证了高效写和范围查询等特点




